Metadata Catalogue
Metadata Catalogue
Exploring soil sample variability through principal component analysis (PCA) using excel data
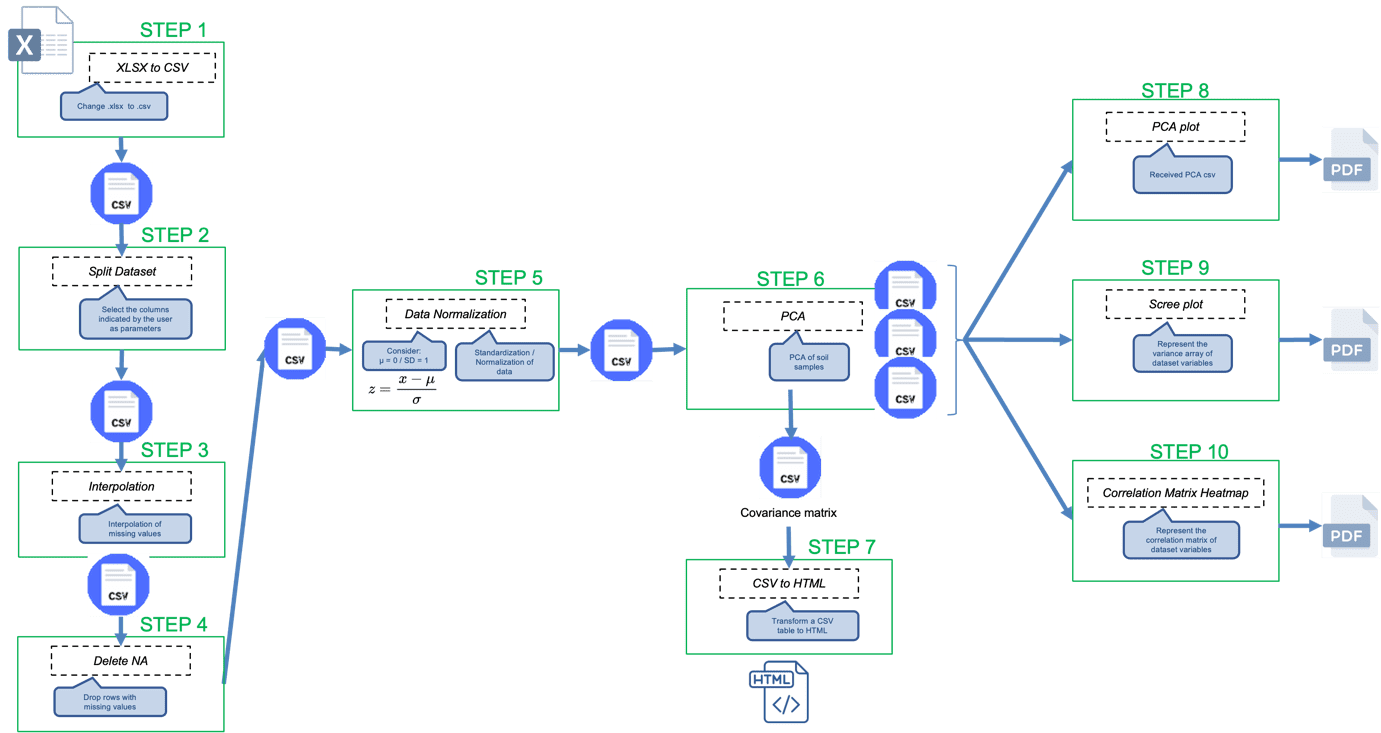
SoilExcel workflow, a tool designed to optimize soil data analysis. It covers data preparation, statistical analysis methods, and result visualization. SoilExcel integrates various environmental data types and applies advanced techniques to enhance accuracy in soil studies. The results demonstrate its effectiveness in interpreting complex data, aiding decision-making in environmental management projects.<div><br><div>Background<div>Understanding the intricate relationships and patterns within soil samples is crucial for various environmental and agricultural applications. Principal Component Analysis (PCA) serves as a powerful tool in unraveling the complexity of multivariate soil datasets. Soil datasets often consist of numerous variables representing diverse physicochemical properties, making PCA an invaluable method for: <div>∙Dimensionality Reduction: Simplifying the analysis without compromising data integrity by reducing the dimensionality of large soil datasets.
∙Identification of Dominant Patterns: Revealing dominant patterns or trends within the data, providing insights into key factors contributing to overall variability.
∙Exploration of Variable Interactions: Enabling the exploration of complex interactions between different soil attributes, enhancing understanding of their relationships.
∙Interpretability of Data Variance: Clarifying how much variance is explained by each principal component, aiding in discerning the significance of different components and variables.
∙Visualization of Data Structure: Facilitating intuitive comprehension of data structure through plots such as scatter plots of principal components, helping identify clusters, trends, and outliers.
∙Decision Support for Subsequent Analyses: Providing a foundation for subsequent analyses by guiding decision-making, whether in identifying influential variables, understanding data patterns, or selecting components for further modeling. </div><div><br></div><div>Introduction</div><div>The motivation behind this workflow is rooted in the imperative need to conduct a thorough analysis of a diverse soil dataset, characterized by an array of physicochemical variables. Comprising multiple rows, each representing distinct soil samples, the dataset encompasses variables such as percentage of coarse sands, percentage of organic matter, hydrophobicity, and others. The intricacies of this dataset demand a strategic approach to preprocessing, analysis, and visualization. To lay the groundwork, the workflow begins with the transformation of an initial Excel file into a CSV format, ensuring improved compatibility and ease of use throughout subsequent analyses.
Furthermore, the workflow is designed to empower users in the selection of relevant variables, a task facilitated by user-defined parameters. This flexibility allows for a focused and tailored dataset, essential for meaningful analysis. Acknowledging the inherent challenges of missing data, the workflow offers options for data quality improvement, including optional interpolation of missing values or the removal of rows containing such values. Standardizing the dataset and specifying the target variable are crucial, establishing a robust foundation for subsequent statistical analyses.
Incorporating PCA offers a sophisticated approach, enabling users to explore inherent patterns and structures within the data. The adaptability of PCA allows users to customize the analysis by specifying the number of components or desired variance. The workflow concludes with practical graphical representations, including covariance and correlation matrices, a scree plot, and a scatter plot, offering users valuable visual insights into the complexities of the soil dataset. <br></div><div><br></div><div>Aims</div><div>The primary objectives of this workflow are tailored to address specific challenges and goals inherent in the analysis of diverse soil samples: </div><div>∙Data transformation: efficiently convert the initial Excel file into a CSV format to enhance compatibility and ease of use.
∙Variable selection: empower users to extract relevant variables based on user-defined parameters, facilitating a focused and tailored dataset.
∙Data quality improvement: provide options for interpolation or removal of missing values to ensure dataset integrity for downstream analyses.
∙Standardization and target specification: standardize the dataset values and designate the target variable, laying the groundwork for subsequent statistical analyses.
∙PCA: conduct PCA with flexibility, allowing users to specify the number of components or desired variance for a comprehensive understanding of data variance and patterns.
∙Graphical representations: generate visual outputs, including covariance and correlation matrices, a scree plot, and a scatter plot, enhancing the interpretability of the soil dataset. </div><div><br></div><div>Scientific questions</div><div>This workflow addresses critical scientific questions related to soil analysis: </div><div>∙Variable importance: identify variables contributing significantly to principal components through the covariance matrix and PCA. </div><div>∙Data structure: explore correlations between variables and gain insights from the correlation matrix. </div><div>∙Optimal component number: determine the optimal number of principal components using the scree plot for effective representation of data variance. </div><div>∙Target-related patterns: analyze how selected principal components correlate with the target variable in the scatter plot, revealing patterns based on target variable values.</div></div></div></div>
Default
- Date ( Publication)
- 2023-12-31T00:00:00
- Status
- On going / operational
- Keywords
-
Soil sample variability
- Keywords
-
Principal Component Analysis (PCA)
- Keywords
-
Dimensionality reduction
- Keywords
-
Data variance
- Keywords
-
Soil datasets
- Keywords
-
Physicochemical properties
- Keywords
-
Data quality improvement
- Keywords
-
Graphical representations
- Keywords
-
Covariance and correlation matrix
- Keywords
-
Scree plot
- Keywords
-
Scatter plot
- Keywords
-
Multivariate analysis
- Access constraints
- Copyright
- Other constraints
-
Copyright 2023 Khaos Research Group
- Service Name
-
XLSX to CSV
- Service Description
-
Change the input XLSX file to CSV
- Service Reference (id)
- Service Name
-
Split dataset
- Service Description
-
Select the columns indicated by the user as parameters
- Service Reference (id)
- Service Name
-
Interpolation
- Service Description
-
Interpolation of missing values
- Service Reference (id)
- Service Name
-
Delete NA
- Service Description
-
Drop rows with missing values
- Service Reference (id)
- Service Name
-
Data Normalization
- Service Description
-
Standardization and normalization of data
- Service Reference (id)
- Service Name
-
PCA Soil
- Service Description
-
PCA of soil samples
- Service Reference (id)
- Service Name
-
CSV top HTML
- Service Description
-
Transform a CSV table to HTML
- Service Reference (id)
- Service Name
-
PCA Plot
- Service Description
-
It represents a plot from the PCA CSV
- Service Reference (id)
-
https://gitlab.lifewatch.dev/lfw002-khaos/wrapper-library/-/tree/develop/data-sink/PCAplot/1.0.0
- Service Name
-
Scree Plot
- Service Description
-
It represents the variance array of dataset variables
- Service Reference (id)
-
https://gitlab.lifewatch.dev/lfw002-khaos/wrapper-library/-/tree/develop/data-sink/ScreePlot/1.0.0
- Service Name
-
Correlation Matrix Heatmap
- Service Description
-
It represents the correlation matrix of dataset variables
- Service Reference (id)
- Workflow Helpdesk
Metadata
- File identifier
- 17fcd35f-499b-45f9-94f4-fe32b08b2d5b XML
- Metadata language
- en
- Hierarchy level
- Workflow
- Metadata Schema Version
-
1.0